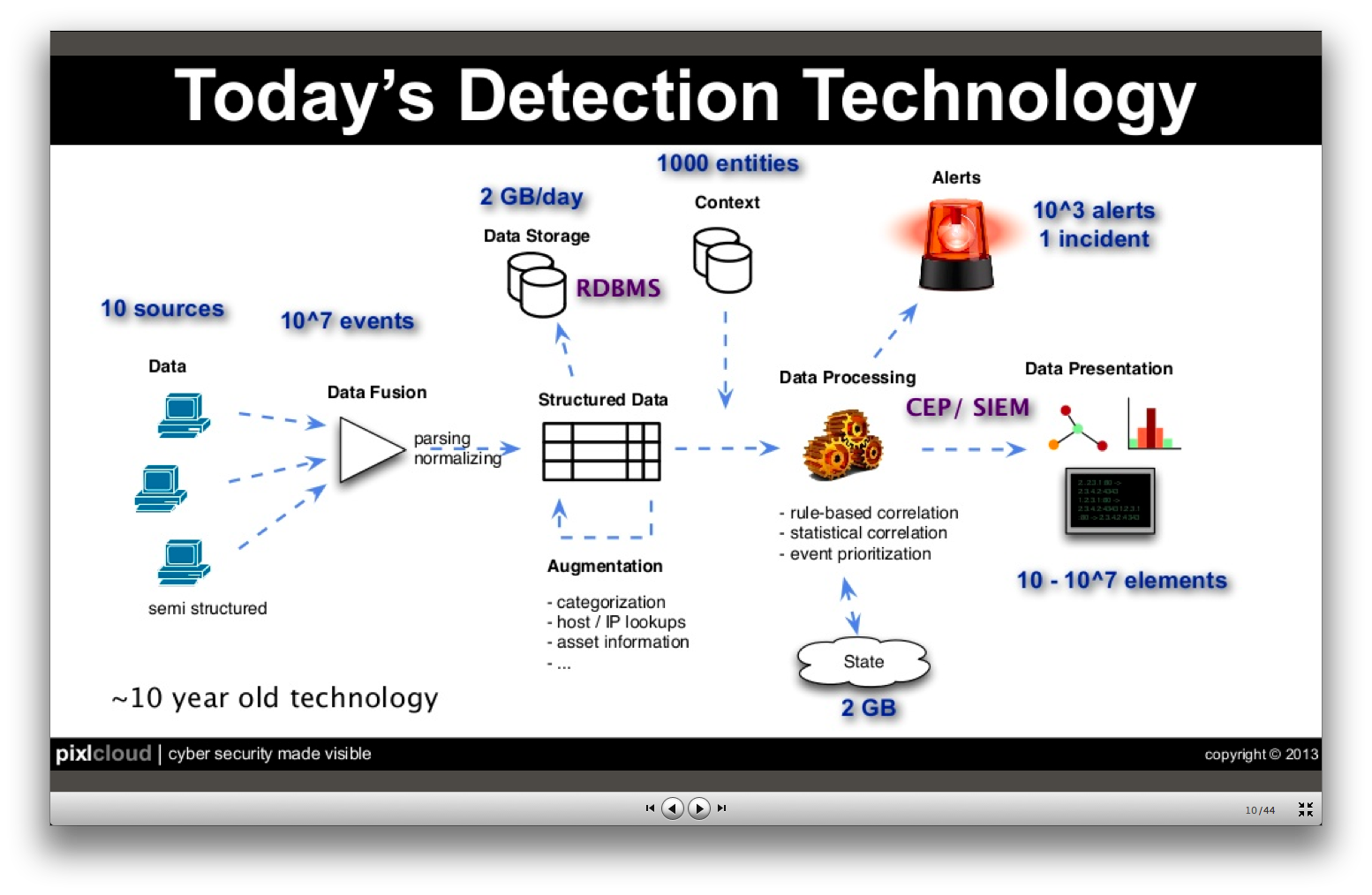
The paper about the Pixel Carpet is one of the results from a collaboration between data visualization researchers from FHP and computer security engineers of various institutions. It builds on the observation that security engineers know their data and the requirements of their work very well. However, they might not be acquainted with advanced visualization techniques. Visualization researchers, on the other hand, know methods to visualize and analyze data but usually lack insight into the specific requirements of computer network security. The paper revolves around two main contributions:
- results and learnings from a co-creative approach of jointly developing visualizations
- a pixel oriented visualization technique that graphically represents multi-dimensional data sets (such as computer log files), reflecting ideas from the collaboration
You can get and read the full paper here (27 MB or 4 MB without video). Please feel free to comment to this post or contact us for any details.
Landstorfer, Herrmann, Stange, Dörk, Wettach (2014): Weaving a Carpet from Log Entries: a Network Security Visualization Built with Co-Creation. in Visual Analytics Science and Technology (VAST), 2014 IEEE Conference on, 2014 (to appear)
Co-creative Approach
User centered approaches are well known in the visualization community (although not always implemented) [D'Amico et al. 2005, Munzner et al. 2009]. Jointly developing the visualizations themselves, however, is rather rare. As we have very good experience with co-creative techniques in design and innovation, we wanted to apply them to the domain of data visualization as well. For example, we tried to experiment with data sets during a day-long workshop with a larger group of stakeholders (a session we called the “data picnic” because everyone brought his/her data and tools).
Visualization
For this paper, we focused on a pixel oriented technique [Keim 2000] to fullfill requirements such as visualization of raw data or a chronological view of data to preserve the course of events. We stack graphical representations for various parameters of a log line (such as IP, user name, request or message) so that we get small columns for each log line. Lining up these stacks produces a dense visual representation with distinct patterns. This is why we call it the Pixel Carpet. Other subgroups of our research group took different approaches that can be found at other places in this blog.
Data and Code
Our data sources included an ssh log (~13.000 lines, unpublished for privacy reasons) and an Apache (web server) access log (~145.000 lines, unpublished), and ~4.500 lines (raw data available, including countries from ip2geo .csv | .json ).
We implemented our ideas in a demonstrator in plain HTML/JavaScript (demo online – caution, will heavily stress your CPU). It helped us iterate quickly and evaluate the idea at various stages, also with new stakeholders. While the code achieves what we need, we are also aware that computing performance is rather bad. If you want to take a look or even improve it, you can find it on github.
To bring it closer to a productive tool, we would turn the Pixel Carpet into a plugin for state-of-the-art data processing engines such as ElasticSearch/Kibana or splunk (scriptable with d3.js since version 6).

![[official pix not available yet]](http://complexdatavisualized.com/wp-content/uploads/2013/09/BigDataPlenum.jpg)



